|
Mukhammadsaid Mamasaidov I'm a 23-years old research scientist, working mostly with natural language processing. I'm a founder of Tahrirchi, an R&D company that develops language solutions for Uzbek, such as spell and grammar checking. I'm also interested in other low-resource Turkic languages, like Kazakh and Kyrgyz. At Tahrirchi I've implemented morphological analyzers for Uzbek and Kazakh, pre-trained large language models for Uzbek, and created a grammar checker for Uzbek, the first of its kind among Turkic languages, by adapting Grammarly's model for Uzbek. I've led a team that won 50k$ at mGovAward 2022, "Best Research Project for the Uzbek Language 2021", and was nominated for "Builder of the Future" of Uzbekistan medal. We also contribute to the open-source community of Uzbek NLP. Recently, we have open-sourced the biggest corpus of Uzbek (36 GB) consisting of more than 35,000 books. Additionally, we also open-sourced several pre-trained language models for Uzbek. |

|
ResearchI'm interested in nature language processing and machine learning. Specifically, I focus on Spelling Correction and Grammatical Error Correction (GEC) tasks. |
|
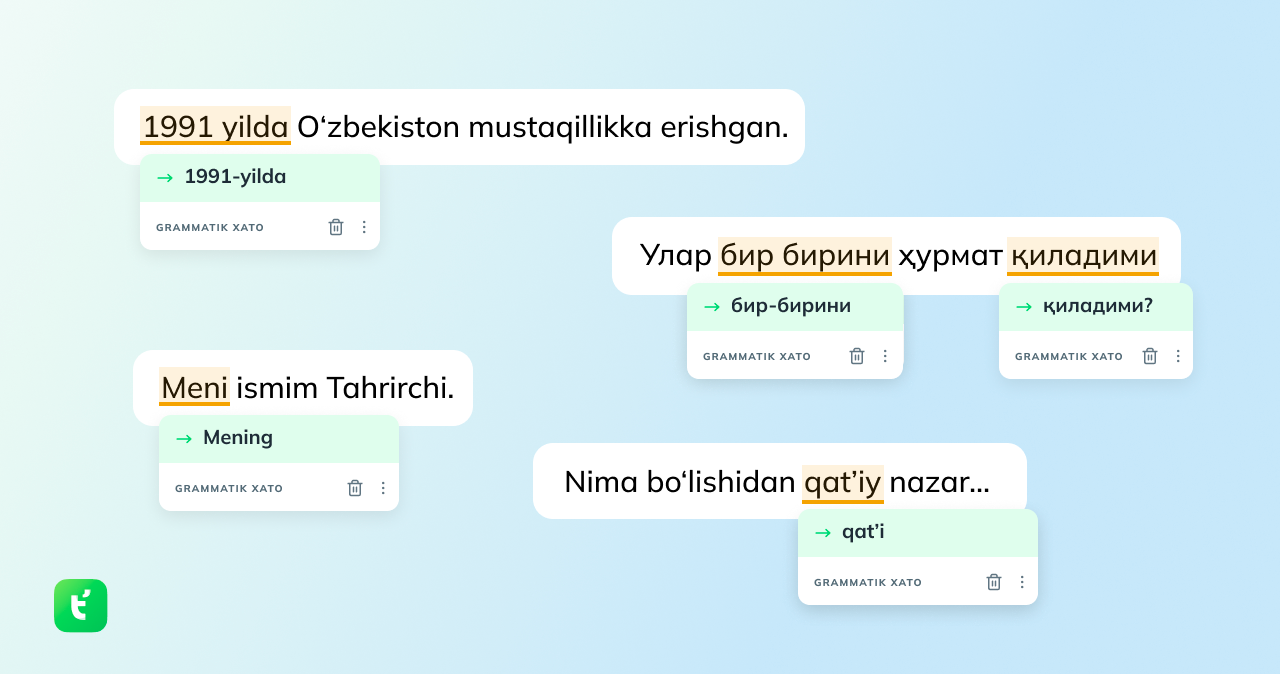
Grammatical Error Correction (GEC) for Agglutinative Languages: Case of Uzbek
Mukhammadsaid Mamasaidov In draft, 2023 project page (in Uzbek) / demo Using Grammarly's GECToR model, we created a grammar checker for Uzbek. The idea is to incorporate the knowledge of rule-based morphological analyzers into the neural network, which makes generalization much greater for agglutinative languages, like Uzbek. |
|
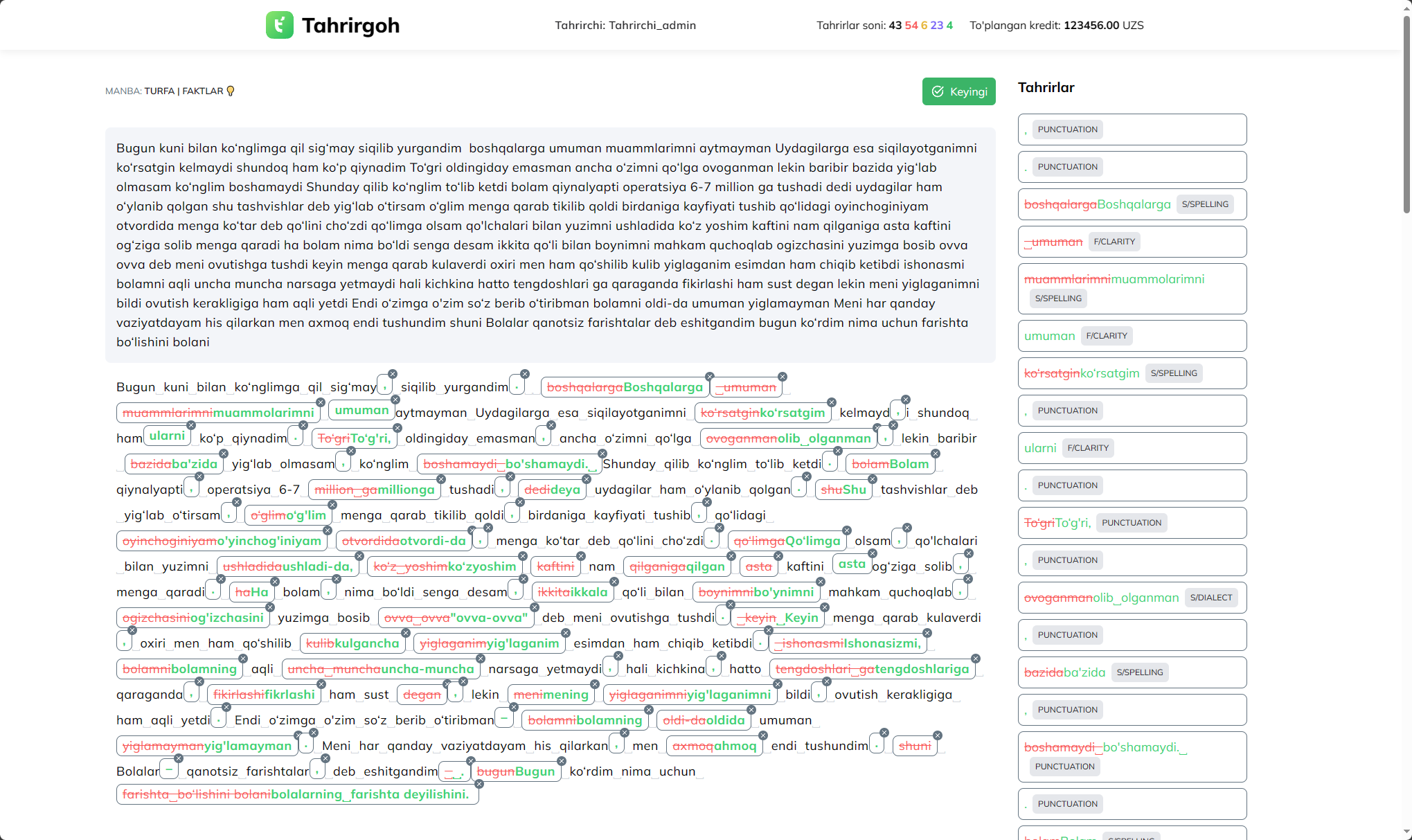
Tahrirgoh: Data Annotation Platform for Grammatical Error Correction
Mukhammadsaid Mamasaidov, Jasur Yusupov 2023 code We created a minimalistic data annotation platform for grammatical error correction data collection. |

|
UzBooks and UzCrawl: the biggest open-sourced Uzbek corpora
Mukhammadsaid Mamasaidov, Abror Shopulatov 2023 UzBooks / UzCrawl We scanned and OCRed more than 35,000 high-quality books in Uzbek. Overall, the dataset size is 33 GB, plus 3 GB of crawled data, like news and articles. It's the biggest high-quality dataset in Uzbek to this date. |

|
A two-level morphological analyzer for Uzbek
Mukhammadsaid Mamasaidov In draft, 2022 video Using finite-state transducers I implemented a morphological analyzer for Uzbek. Then, I formed a team and created a soft mobile keyboard only for Uzbek, with its agglutinative nature in mind. We won 50k$ at mGovAward 2022 as the best mobile application for the government. |

|
UZWORDNET: A Lexical-Semantic Database for the Uzbek Language
Alessandro Agostini, Timur Usmanov, Ulugbek Khamdamov, Nilufar Abdurakhmonova Mukhammadsaid Mamasaidov GWC, 2021 project page / ACL We describe the initial development of a “word-net” for the Uzbek language compatible to Princeton WordNet. To the best of our knowledge, it is the largest wordnet for Uzbek existing to date, and the second wordnet developed overall. |
|
Feel free to steal this website's source code. |